Quatro estratégias de proteção para ambiente virtual
A virtualização é uma estratégia fundamental nos ambientes de TI. Essa tecnologia sem dúvidas trouxe várias vantagens como gerenciamento simplificado e o efetivo uso dos recursos computacionais. Entretanto, com menos servidores físicos e maior número de máquinas virtuais, os administradores de TI se deparam com uma série de mudanças na proteção de dados e nos desafios de backup. Hoje, a proteção para ambiente virtual é mais do que fazer uma cópia de arquivos de dados, cada máquina virtual precisa estar segura e disponível.
É por isso que cada vez mais as organizações estão repensando suas estratégias de proteção, de forma que consigam chegar a uma tecnologia que supra as necessidades particulares ao ambiente virtualizado. Para ajudar você nesse processo, separamos quatro estratégias de proteção para ambientes virtuais.

Por que repensar a proteção para o ambiente virtual?
A primeira estratégia que se pensa quando se trata de proteção de dados é o backup. Afinal, se tudo der errado, há sempre uma cópia guardada para ser restaurada. Entretanto, em ambientes virtuais, esse processo é muitas vezes complexo, lento e afeta o desempenho da produção. [Veja mais em Por que a consolidação dificulta o desempenho do backup] Por esse motivo, algumas tecnologias como replicação e proteção de dados se mostram cada vez mais eficientes na proteção de data centers consolidados.
Isso não quer dizer que você deve descartar o backup e substituir por essas outras metodologias, afinal, ele é um componente chave para a proteção de dados. A ideia é justamente o contrário, unindo backup com replicação e proteção e dados contínua é possível obter mais eficiência e menor risco em ambientes virtualizados.
Para que você possa escolher quais tecnologias são as mais adequadas a realidade do seu ambiente virtual, selecionamos as quatro estratégias principais de proteção: método tradicional de backup, backup baseado em imagem, replicação e proteção de dados contínua.
Estratégia 1 – Método Tradicional de Backup
No método tradicional de backup, o agente de backup pode ser instalado tanto no nível de máquina virtual como no de hypervisor. No primeiro caso, o agente realiza o backup dentro e cada máquina virtual com uma configuração parecida com a de uma máquina física. Esse tipo de processo pode ser realizado em conjunto com software tradicional de backup ou apenas com o agente de backup do próprio software de virtualização.
A vantagem de proteger o ambiente virtual com software de backup tradicional é que não há diferença entre o modo de realizar o backup dos ambientes virtuais e não-virtuais, porém esse método pode ser muito custoso. Afinal, softwares tradicionais tratam cada máquina virtual como uma física, o que significa, adquirir licenciamento da aplicação de backup para cada VM. Isso é inviável em organizações de grande porte, onde há mais de 40 máquinas virtuais, por exemplo.
Já os agentes de backup são inclusos no próprio software de virtualização para auxiliar os administradores a integrar as máquinas virtuais aos processos tradicionais de backup. A maior vantagem desse método é o custo: esses agentes são de graça ou podem ser adicionados a um valor mínimo. Entretanto, há muitas limitações, a principal é que não é possível escolher quais volumes ou sistemas operacionais serão copiados. A única opção é copiar todo o sistema. Igualmente, a recuperação também só pode ser feita do conjunto inteiro, não há a possibilidade de recuperar uma porção da VM, ou verificar se os dados estão íntegros.
No segundo caso, o agente de backup opera no nível do hypervisor. Para que isso ocorra, o agente interpreta as máquinas virtuais como um conjunto de arquivos. Assim, os arquivos das máquinas virtuais podem ser copiados como se fossem um sistema de arquivos do hypervisor.
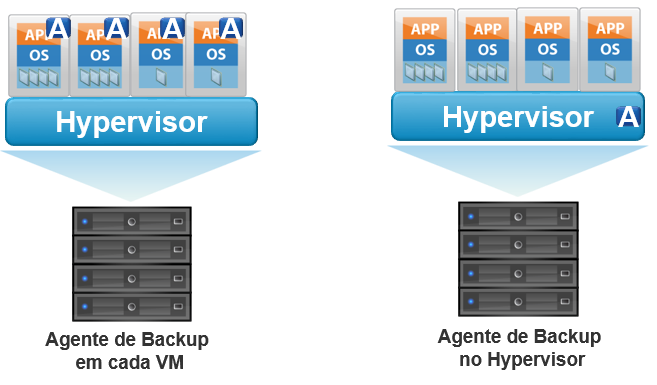
Esse método é relativamente simples porque apenas requer um agente, ao invés de um em cada máquina virtual do hypervisor.
O grande problema de realizar backup tradicional é que como o processo ocorre dentro da máquina virtual ou no hypervisor, ele consome muito desempenho do sistema e pode ocasionar em lentidão das VMs. Isso ocorre porque ao mesmo tempo em que as aplicações estão rodando, o backup é realizado na mesma camada. Além disso, pode ser mais custoso do que os outros tipos, afinal, ou você realiza com software tradicional e paga por licença de cada máquina virtual, ou faz por agentes de backup do software de virtualização e perde em rede, armazenamento e processamento, já que desse modo só existe a possibilidade de realizar o backup integral do sistema.
Estratégia 2 – Backup Baseado em Imagem
O Backup baseado em Imagem ocorre no nível do hypervisor e é essencialmente através da criação de um snapshot da máquina virtual. Dessa forma, ele cria uma cópia do sistema operacional da máquina virtual e de todos os dados associados à ela, incluindo estado da VM e configuração das aplicações.
Esse backup salva tudo em um único arquivo denominado imagem, e essa imagem é montada em um servidor físico proxy, o qual atua como um cliente de backup. Após esse processo, o software de backup copia esses arquivos de imagem normalmente. Isso diminui efetivamente o processamento de backup no hypervisor e transfere o processamento para o servidor proxy, reduzindo assim, o impacto no desempenho das máquinas virtuais que rodam no hypervisor.
O backup baseado em imagem também permite uma rápida recuperação da máquina virtual, já que todo o estado da máquina está salvo em um único conjunto. Outra vantagem é que o snapshot geralmente é feito em poucos minutos ou menos e na maioria dos casos os usuários nem sequer reparam que está sendo realizado. Ele pode ser feito de maneira completa e capturar a máquina virtual inteira ou incremental e capturar apenas as mudanças ao longo do tempo. Uma vez que o backup é capturado para o armazenamento, o snapshot pode ser usado de várias maneiras importantes. Pode ser replicado – ou espelhado – para um local remoto que facilite a recuperação de desastres, pode ser clonado para outros servidores, e pode também ser copiado para um servidor dedicado de backup que poderá movê-lo para uma fita.
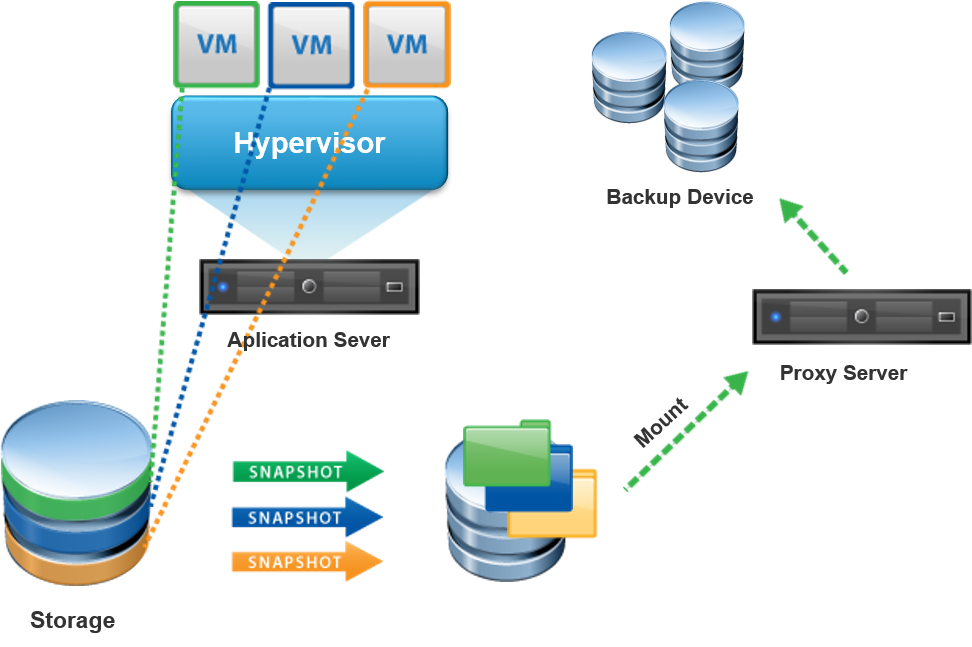
É interessante perceber que os snapshots requerem espaço de armazenamento e gerenciamento, afinal ao longo do tempo haverão várias cópias similares que podem comprometer o armazenamento.
Estratégia 3 – Replicação Local e Remota
Replicação é o processo de criação de uma cópia exata (réplica) do dado. Essas réplicas são usadas para restaurar as operações, caso haja perda de dados. Ela é diferente do backup pelo fato de que é imediatamente disponível às aplicações, o que não acontece com o backup, afinal o backup precisa ser restaurado pelo software de backup para se tornar acessível a elas. A replicação pode ocorrer de duas formas: local ou remota.
Replicação Local
Replicação local necessariamente ocorre no mesmo data center ou array. No contexto de máquinas virtuais, a replicação local pode ser realizada no nível do storage, usando array-based local replication, ou no hypervisor. No primeiro caso, a LUN em que cada máquina virtual se encontra é replicada para outra LUN no mesmo array. Já no segundo caso, hypervisor, existem dois modos de realizar a replicação, através de snapshot ou clone.
O snapshot da máquina virtual captura o estado e os dados da máquina virtual em um ponto do tempo. Isso significa que se a máquina falhar, o snapshot consegue trazer ela de volta no mesmo estado em que estava no ponto do tempo em que foi realizado. O estado contém arquivos da VM, como a BIOS e configuração de rede, já os dados da máquina virtual incluem todos os arquivos que a compõem, incluindo discos virtuais e memória.
Esse processo funciona através de um sistema de ponteiros, os quais informam todas as configurações da máquina no estado atual, caso alguma mudança seja realizada durante a sua realização, ele as grava em um ambiente separado. Snapshots são úteis quando a VM precisa ser revertida a um estado anterior ao evento da corrupção lógica. Entretanto, existem alguns desafios relacionados à tecnologia de Snapshot de máquinas virtuais. Ela não suporta replicação de dados se a máquina virtual acessa um disco apresentado diretamente à ela (raw disk) e também impacta a performance da VM, já que é realizada no nível do hypervisor.
O clone de máquina virtual é um outro método de replicação a nível de hypervisor que, como o próprio nome já diz, cria uma cópia idêntica. Quando a operação de clonagem se completa, o clone se torna uma máquina virtual separada. Ele tem seu próprio endereço de MAC, e as alterações feitas no clone não afetam a máquina virtual original. Da mesma forma, as mudanças feitas na cópia original não afetam o clone. O clone é um método útil em casos de necessidade de produção de várias máquinas virtuais idênticas.
Replicação Remota
Replicação remota é o processo de criação de réplicas dos ativos de informação em sites remotos (locais diferentes). Esse tipo de replicação ajuda a reduzir os riscos associados a interrupções regionais causadas por desastres naturais ou falhas humanas. Durante a interrupção, toda a operação do data center desligado pode ser transferida para o site remoto, garantindo a continuidade do negócio. Além disso, a replicação remota também pode ser usada em outras operações como testes, backup, etc.
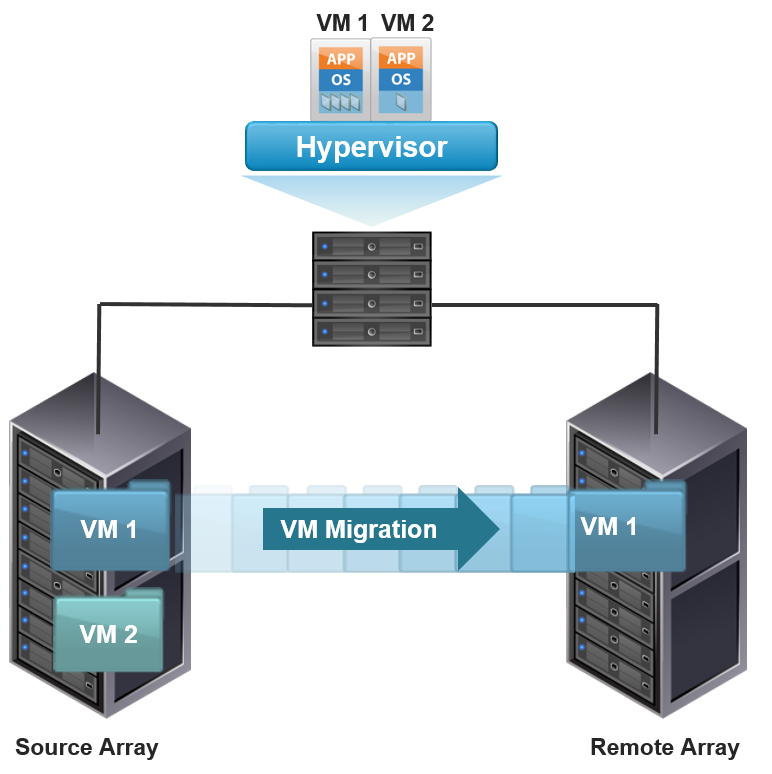
Em ambientes virtualizados, a replicação remota ocorre de maneira simples e invisível às máquinas virtuais. Nesse cenário, todas as VMs e suas configurações de arquivos que estão no storage array do site primário são replicadas para o storage array do site remoto. Esse processo pode ocorrer de duas formas: através da replicação das LUNs ou pela migração das máquinas virtuais entre os dois sites.
No primeiro método, as LUNs são replicadas entre os dois sites usando a tecnologia storage array. Esse processo de replicação pode ser tanto síncrono (antes de o dado ser gravado no site de produção, ele deve ser gravado no segundo – RPO próximo de zero) como assíncrono (o dado é gravado no site de produção e depois é enviado ao remoto – RPO diferente de 0).
A migração de máquinas virtuais é uma outra técnica usada para garantir continuidade de negócios em caso de falha no hypervisor ou manutenção programada. A migração é um processo que move as máquinas virtuais de um hypervisor para outro sem ocorrer desligamento das máquinas virtuais. A migração ajuda também no balanceamento de carga quando múltiplas máquinas virtuais rodam na mesma camada competindo por recursos do mesmo hypervisor. Duas técnicas são comumente usadas para a migração de máquinas virtuais: hypervisor – hypervisor ou array-array.
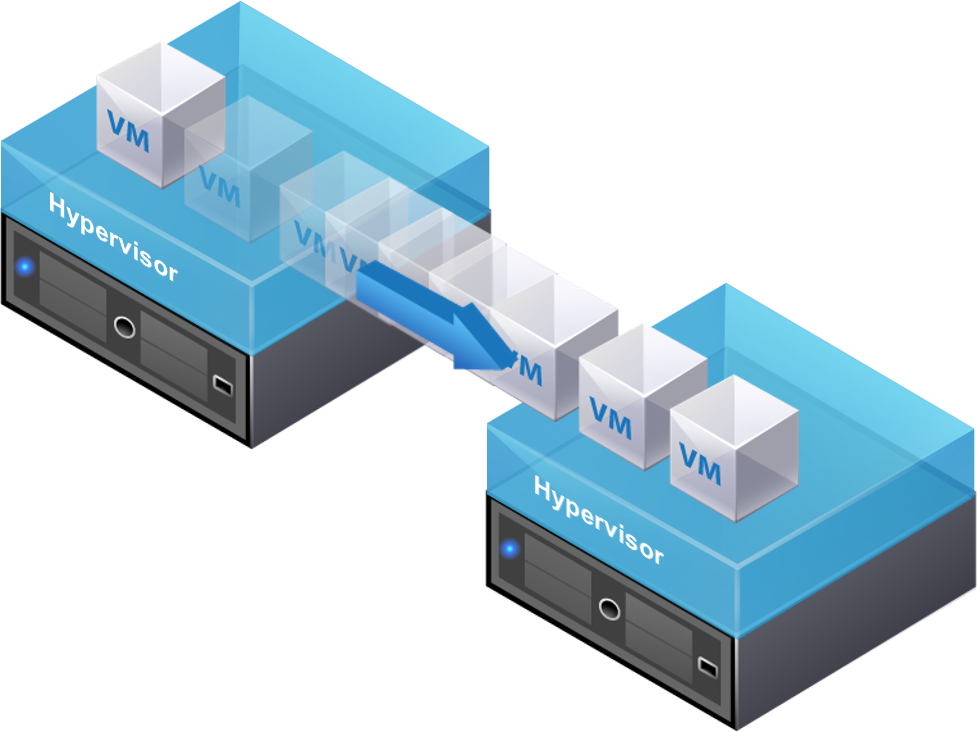
Esse método copia todo o conteúdo da memória da máquina do hypervisor de origem para o destino e então transfere o controle dos arquivos do disco da VM para o hypervisor de destino.
No método de migração hypervisor- hypervisor, todo o estado ativo da máquina virtual é movido de um hypervisor para o outro. Como os discos virtuais das VMs não foram migrados, essa técnica requer que ambos hypervisors, origem e destino, acessem o mesmo storage.
No método de migração array-array, os discos virtuais são movidos do array de origem para o remoto. Esse método permite que o administrador mova as VMs através de storage arrays diferentes. A migração Array-to-array começa pela cópia do metadado da VM da origem para o destino. O metadado essencialmente consiste na configuração, swap e arquivos de log. Após isso, os arquivos de discos são replicados para o novo local. Durante a replicação, pode ocorrer de a origem ser atualizada, o que não é problema, já que esse método rastreia essas mudanças para manter os dados do site remoto íntegros. Após a completa replicação, os blocos que foram alterados na origem após o início da replicação são replicados para o novo local. Array-to-array melhora a performance e balanceia a capacidade do storage pela redistribuição dos discos virtuais entre diferentes dispositivos.
A replicação remota possui algumas limitações.
Como ela cria uma cópia idêntica do site primário no remoto, qualquer falha pode ser imediatamente, ou de maneira rápida, transmitida para o segundo site. O que pode ocasionar na perda, não só do ambiente de produção, como o de proteção. Um outro ponto que merece atenção é o fato de que a replicação é apenas uma cópia exata atual, ela não possui versões históricas do dado, como registro de como o ambiente estava dias atrás, semanas e meses, como o backup e a proteção contínua têm.
Proteção de dados contínua
O conceito da proteção de dados contínua é bem interessante. Essa tecnologia realiza tantos snapshots que funciona como se fosse uma filmagem do sistema. Por causa disso é possível rastrear e armazenar todas as atualizações dos dados. A grande vantagem dessa solução é a alta granularidade, ou seja, ela possui a capacidade de voltar em qualquer ponto no tempo, por mais próximo que seja. Isso resolveu um grande desafio das tecnologias de proteção de dados tradicionais, os pontos de recuperação limitados. Esse problema limitava a recuperação do sistema em caso de dado corrompido, afinal só era possível recuperar o último ponto de recuperação disponível.
Na proteção de dados contínua as alterações nos dados são capturadas a todo o momento e armazenadas em um local separado do armazenamento primário. Além disso, os RPOs não precisam ser configurados, pois podem ser qualquer um ao longo do tempo. Com essa tecnologia é possível voltar até segundos antes de o dado ser corrompido. Ela é ideal em ambientes críticos que não podem haver perda de dados. Pode ser usada também junto com o backup e a replicação de maneira muito eficiente, pois ela consegue resolver problemas de dados corrompidos, mesmo se esse dado for replicado, e também evita que o backup seja utilizado para recuperações mais simples, o que traz economia em desempenho e rede.
Qual estratégia de proteção para ambiente virtual é a melhor para você?
Uma boa estratégia de proteção de dados combina um número de aspectos que incluem backup, replicação e proteção de dados contínua.
A replicação é uma excelente estratégia para balancear a carga de trabalho das máquinas virtuais, minar os riscos de perda de dados em caso de desastres naturais ou falhas humanas. Além disso, essa tecnologia permite que se um site falhar o outro pode assumir de maneira muito rápida, sem precisar recuperar o dado e o seu contexto, já que todo o ambiente é similar ao ambiente primário.
A proteção de dados contínua consegue suprir a limitação da replicação e dar mais eficiência à recuperação dos dados. Muitas vezes a janela de exposição do backup é de 24 horas, ou seja, o backup foi realizado a noite e só será feito novamente na próxima noite, se algo acontecer entre esse período a organização poderá perder até 24 horas de dados. Mesmo se o data center possuir replicação, ele não estará isento desse tipo de risco, afinal uma falha pode passar para o outro site de forma síncrona ou assíncrona. Nesse caso, a proteção de dados contínua consegue voltar até um segundo antes de a falha ocorrer, ou seja a granularidade dessa tecnologia é a sua grande vantagem.
Finalmente, o backup é a salvaguarda da informação, é essencial e deve ser realizado não só no ambiente virtual como em todas as aplicações de um data center. No entanto, backups tradicionais não necessariamente provêm a flexibilidade ou a eficiência que algumas aplicações necessitam. Por exemplo, alguns sistemas precisam estar disponíveis 24×7, ou seja, não podem parar. O backup não atende a essa necessidade, pois geralmente tem janelas mais longas e seu tempo de recuperação é mais lento. Em um cenário ideal, o backup é o último recurso que deve ser utilizado em caso de perda de dados. Primeiro você deve contar com outras tecnologias de proteção pensando em alta disponibilidade, continuidade de negócios e aí você tem o backup como salvaguarda de informações.
Uma estratégia eficiente de proteção de dados utiliza a combinação de todas essas soluções, aplicando-as em diferentes níveis de serviços de acordo com as necessidades de cada aplicação e da organização.