O que é desduplicação e o que sua empresa precisa saber
As organizações lidam como crescimento de dados a cada minuto. Trabalhar com o crescimento não é pouca coisa e proteger os dados de forma eficaz é um desafio ainda maior. Uma maneira de obter vantagem sobre o backup de dados tradicional é literalmente reduzir o tamanho dos dados utilizando a tecnologia de desduplicação de dados.

Há alguns anos, o uso de disco na arquitetura de backup trouxe mudanças bastante radicais e benefícios para as operações de backup da a maioria das empresas. Hoje é possível obter ainda mais ganhos no armazenamento, rede e desempenho de backup, unindo o uso do disco com a tecnologia de desduplicação. A tecnologia de desduplicação eleva ainda mais o backup baseado em disco. A grande inovação da desduplicação é a capacidade de eliminar os dados redundantes de backup, os quais costumavam exigir centenas de terabytes de disco e que agora podem ser reduzidos em um décimo – ou ainda menos – do tamanho original.
Há uma grande variedade de tecnologias de desduplicação para atender às necessidades da maioria das organizações de todos os portes. Você pode implementar desduplicação por meio de software, em um appliance específico para backup ou em uma biblioteca de fita virtual.
Neste artigo, você terá informações importantes para saber avaliar a tecnologia de desduplicação correta que atenda as suas necessidades de backup e recuperação de dados. Saiba mais sobre os níveis de desduplicação (arquivo, bloco fixo ou variável), onde os dados duplicados serão examinados (origem ou destino) e quando os dados serão desduplicados (in-line ou pós-processamento).
Desduplicação em nível de arquivo e de bloco
Para identificar duplicidades, os dados podem ser analisados em diferentes formas, dependendo da tecnologia utilizada. Na desduplicação em nível de arquivo, também chamada de armazenamento de instância única (SIS), os arquivos que serão copiados são comparados com arquivos que já foram armazenados. Se o arquivo é único, ele é armazenado e o índice é atualizado; se não, apenas um ponteiro para o arquivo existente é armazenado. O resultado é que apenas uma cópia do arquivo é salva e as cópias subsequentes são substituídas por ponteiros que direcionam ao arquivo original.
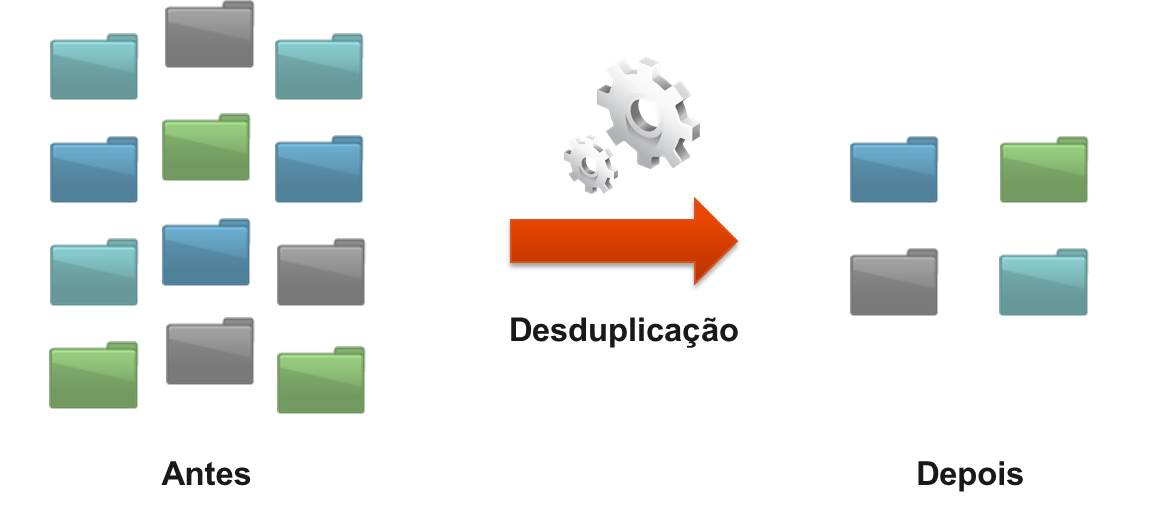
A desduplicação em nível de arquivo
é útil em alguns cenários, como em um servidor de arquivos, por exemplo, em que vários usuários eventualmente salvam o mesmo arquivo repetidas vezes em diferentes locais. Nesse caso, a desduplicação em nível de arquivo verifica as redundâncias e salva apenas uma cópia do arquivo com diversos ponteiros apontando para este local. A desvantagem da desduplicação no nível de arquivo é a sua falta de granularidade e incapacidade de fornecer desduplicação no nível do subarquivo. Isso significa que mesmo a menor mudança em um arquivo, como a mudança do título, por exemplo, fará com que um novo arquivo que seja armazenado.
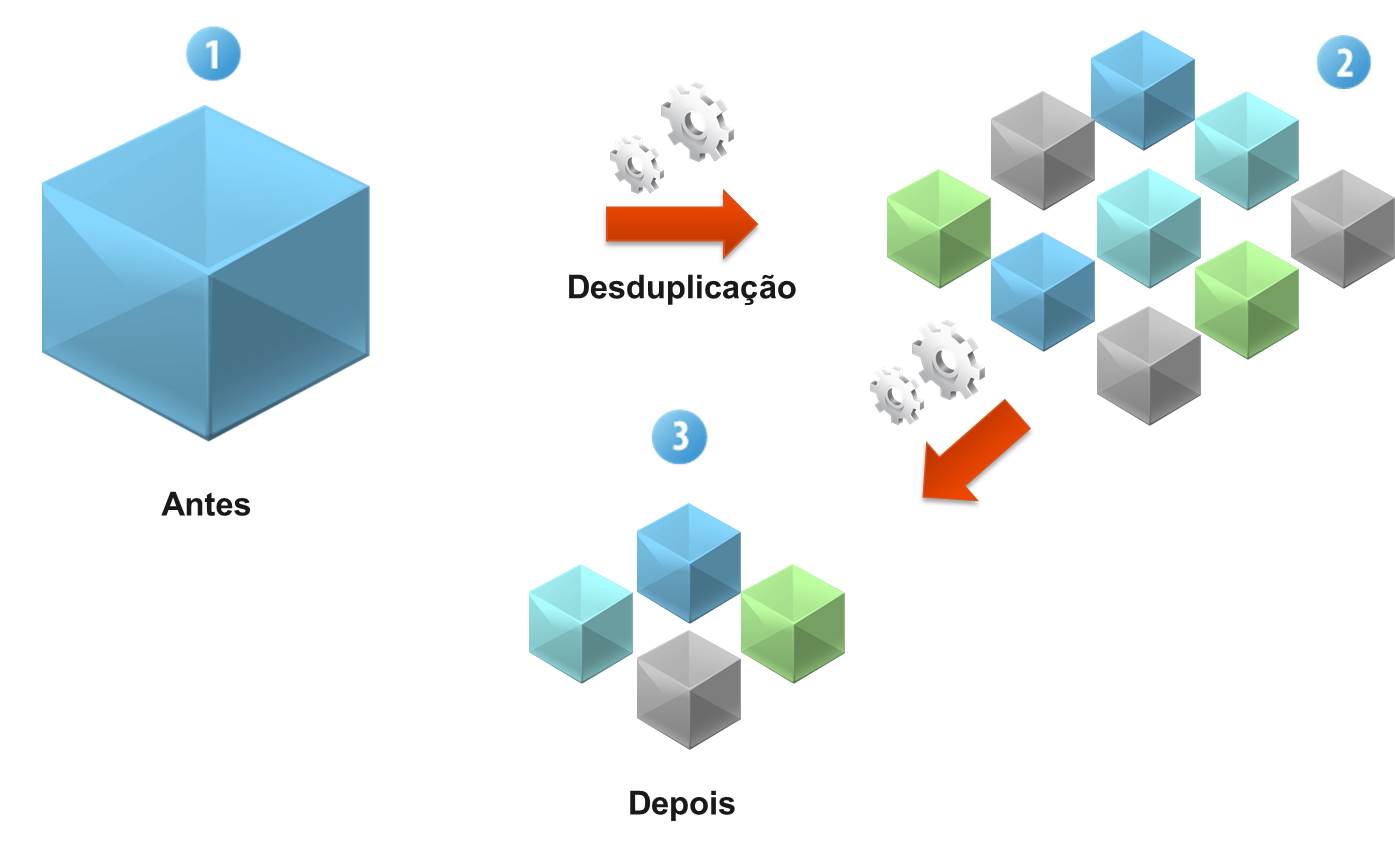
A desduplicação de bloco opera no nível do sub-arquivo e pode ser de comprimento fixo ou variável.
Como o próprio nome indica, o arquivo é normalmente dividido em segmentos – pedaços ou blocos – que são examinados para redundância em relação a informações armazenadas anteriormente.
A desduplicação de comprimento fixo se vale de um algoritmo que divide um sistema de arquivos em segmentos de dados de mesmo comprimento. A principal limitação dessa abordagem é o fato de que, quando os dados em um arquivo são alterados (por exemplo, quando se adiciona um slide a uma apresentação do Microsoft PowerPoint), todos os blocos subsequentes no arquivo serão regravados e provavelmente serão considerados diferentes com relação ao arquivo original.
A desduplicação de comprimento variável é uma abordagem mais avançada, que posiciona segmentos de comprimento variável com base em seus padrões de dados internos. Isso soluciona o problema de alteração de dados com relação à abordagem de blocos de comprimento fixo.
Através desse nível de desduplicação, os conjuntos de dados são divididos em pedaços menores de comprimento variável e os algoritmos atuam para atribuir a cada pedaço de dados um identificador de hash, que compara com identificadores armazenados anteriormente para determinar se o pedaço de dado já foi armazenado.
Essa é abordagem mais efetiva em termos de benefícios, incluindo a menor necessidade de espaço de armazenamento, o uso do espaço em disco mais eficiente e menos dados enviados através de uma LAN ou WAN para backups remotos, replicação e recuperação de desastres.
Desduplicação In-line X Pós-Processamento
Outra opção a considerar é em que momento os dados são desduplicados. A desduplicação In-line remove as redundâncias antes de os dados serem gravados. Isso reduz a quantidade de dados duplicados e o espaço necessário para o backup. No entanto, o processo de backup tende a ser mais lento, já que os dados só serão armazenados após sua desduplicação.
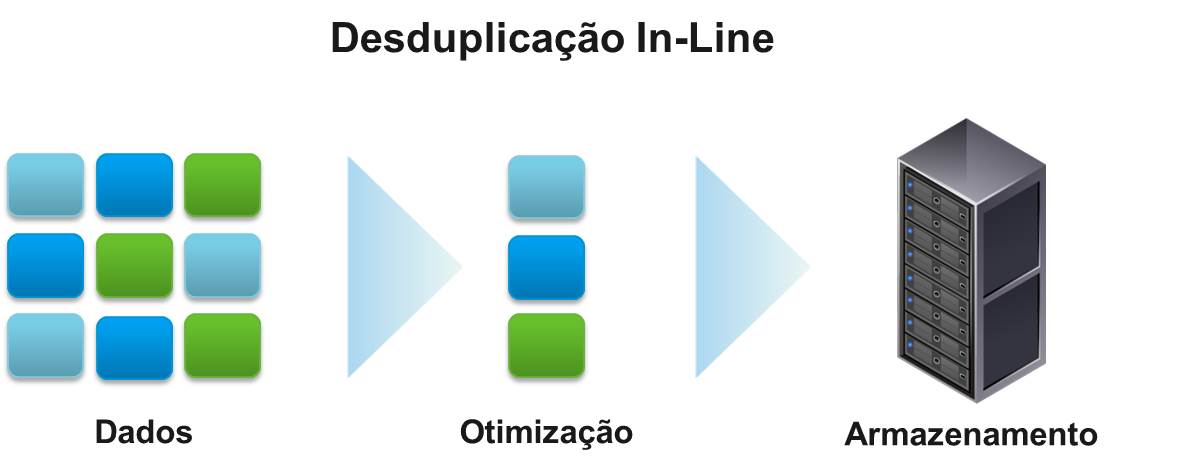
No entanto, o conjunto completo de dados de backup é transmitido através da rede para o appliance antes de as redundâncias serem eliminadas. Por isso é preciso ter rede adequada e disponível para a transferência de dados e capacidade de armazenamento do conjunto completo de dados de backup e dos dados desduplicados.
Desduplicação na Origem X Destino
A desduplicação pode ser realizada por software rodando em um servidor (origem) ou em um appliance em que os dados de backup são armazenados (destino).
A desduplicação na origem é a remoção de redundâncias dos dados no ambiente de produção antes de serem transmitidos para o servidor ou appliance de backup. A desduplicação na origem é feita através de um software que se comunica com o servidor ou appliance de backup para comparar novos blocos de dados com blocos previamente armazenados. Se o servidor ou appliance tiver armazenado anteriormente algum bloco de dados, ele não será enviado pela rede.
O benefício principal da desduplicação na origem é a redução do uso da rede e, por consequência, maior eficiência no armazenamento. Por outro lado, ao realizar a remoção de redundâncias no ambiente de produção, ela compartilha o processamento utilizado por outras aplicações em funcionamento, o que pode impactar esse ambiente, caso o projeto não seja bem dimensionado.
A desduplicação na origem é bem adequada para o backup de sites menores e remotos porque o aumento da utilização da CPU no processo de backup não causam grande impacto. Ambientes virtualizados também são recomendados para a desduplicação na origem por causa das imensas quantidades de dados redundantes em arquivos de disco da máquina virtual (VMDK).
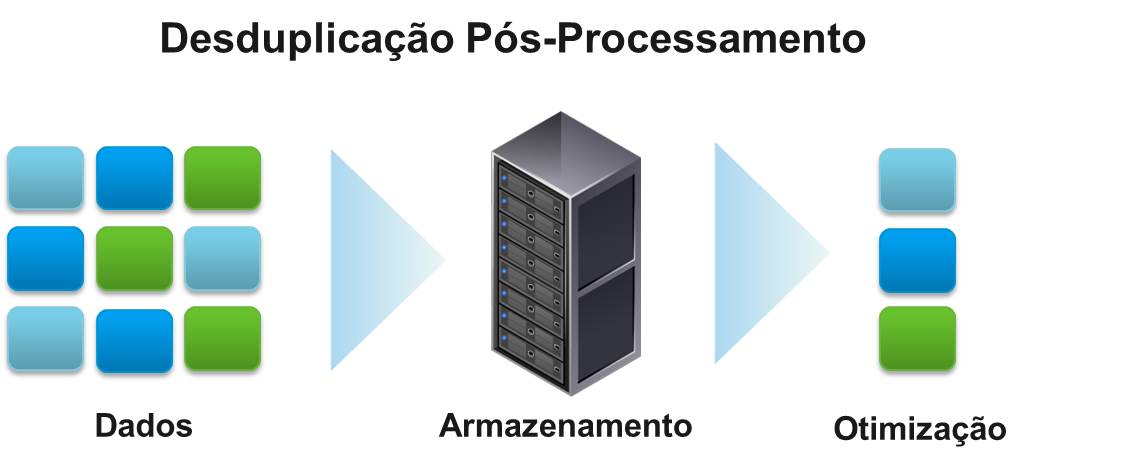
A desduplicação no destino é a remoção de redundâncias dos dados no appliance de backup após o envio pela rede. Essa forma de desduplicação tende a impactar menos o processamento do ambiente de produção. No entanto, a largura de banda é bastante utilizada, já que todos os dados (redundantes ou não) são enviados ao appliance de backup para a desduplicação e armazenamento.
Em casos de janela limitada para backup ou ambientes com altas cargas de trabalho no ambiente de produção, como banco de dados, a desduplicação no destino é recomendada, pois reduz o impacto sobre o processamento da produção.
Avaliando a desduplicação para sua organização
As organizações enfrentam um dilema: armazenar e gerenciar volumes de dados cada vez maiores e, ao mesmo tempo, reduzir os custos. Os benefícios da deduplicação são inegáveis para esses objetivos. Redução do volume de dados do backup, do tempo de recuperação e dos custos de processamento, armazenamento e uso da rede respondem a esses desafios.
Tal como acontece com todos os produtos de backup e armazenamento de dados, as tecnologias utilizadas são apenas um fator que você deve considerar ao avaliar potenciais sistemas de desduplicação.
A chave para alcançar uso efetivo da tecnologia de desduplicação de backup é implementar o método de redução de redundância (ou métodos) que são mais adequados para as necessidades específicas da sua organização.