Saiba como a desduplicação em bloco reduz o volume de dados
Todos os anos o volume de dados no mundo aumenta e as organizações necessitam de soluções que garantam a eficiência em termos de orçamentos de TI, capacidade do datacenter, refrigeração e espaço ocupado. Segundo estudo do IDC, entre 2013 e 2020, o universo digital cresceu cerca de dez vezes o seu tamanho. Não é possível dar conta de um aumento dessa magnitude sem tecnologias que busquem a redução do volume de dados. Por causa disso, a desduplicação em bloco e a compressão ganharam destaque nas soluções de backup, armazenamento e rede atuais.

Como falamos no post “O mito de que a compressão é igual a desduplicação”, essas tecnologias são bem diferentes, mas servem para o mesmo propósito, diminuir as redundâncias dos dados. Explicamos também que a desduplicação a nível de arquivo possui algoritmos que eliminam os arquivos redundantes e criam apenas uma cópia no local de armazenamento. Já a compressão reduz o tamanho de cada dado, ou seja, ainda vão existir a mesma quantidade de arquivos no local de armazenamento, porém cada um terá um volume menor de bytes do que o original.
Entretanto, existem situações em que essas duas tecnologias não conseguem reduzir consideravelmente o volume de dados, nesses casos, a desduplicação a nível de bloco pode ser a solução.
Como funciona a desduplicação em bloco?
Para exemplificarmos melhor esse conceito, vamos comparar a desduplicação a nível de bloco com a tabela periódica dos elementos. O objetivo da tabela é definir todos os elementos químicos únicos que, combinados em devida proporção, possibilitam a reprodução de qualquer matéria conhecida.
Por exemplo, a água potável é H2O e a água oxigenada (peróxido de oxigênio) é H2O2. Basta ter um “H” e um “O” armazenados, e combiná-los. A desduplicação é algo similar: ela armazena blocos únicos de dados que, combinados em determinada ordem e quantidade, reproduzem a informação que precisa recuperar para sua produção.
Esse processo funciona da seguinte forma, os algoritmos dessa solução, denominados hash, dividem o dado em segmentos e dão uma identificação única a cada um de acordo com suas especificações binárias. Em seguida verificam se essas identidades já estão salvas no destino, caso alguma esteja, eles eliminam esses segmentos e inserem ponteiros na cópia única, caso não esteja, salvam no diretório. As instruções para a restauração são gravadas nos meta-dados de cada dado. Assim, quando for necessário, o algoritmo interpreta essas instruções e realiza a restauração.
Exemplificando
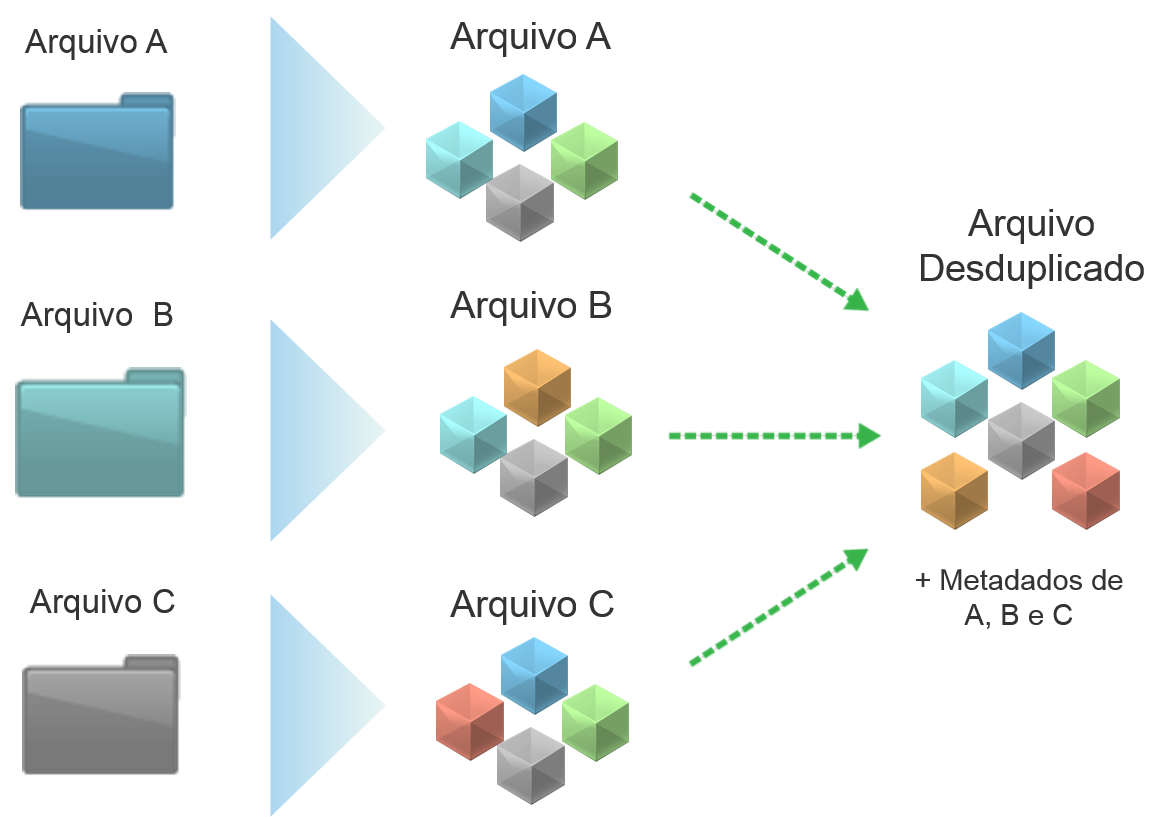
Vamos supor que três arquivos diferentes A, B e C irão sofrer um processo de desduplicação em nível de bloco.
A imagem acima mostra os arquivos antes da quebra em segmentos pelo hash. Ao quebrar os arquivos, cada segmento ganha uma identificação.
Com a identificação, o algoritmo verifica se o segmento está salvo. Caso esteja, é eliminado, caso não, será salvo no diretório. Após essa desduplicação, os arquivos se transformam em um único conjunto, porém, cada um mantém seus meta-dados, os quais possuem as instruções para a remontagem do arquivo.
Note que o primeiro arquivo não teve redução de tamanho, porém os arquivos B e C reduziram em 75%. Isso significa que a medida que os dados são salvos a taxa de redução aumenta, pois a probabilidade desse dado já estar armazenado é maior. Na hora da restauração do dado, o algoritmo da desduplicação faz igual a tabela periódica, utiliza os elementos únicos para remontar os arquivos de acordo com as instruções do meta-dado de cada.
Tipos de desduplicação em bloco
A desduplicação pode ser de comprimento fixo ou variável. O primeiro tipo segmenta os dados em blocos de tamanho fixos que podem ser, por exemplo, de 8 KB ou 64 KB. A partir daí, é identificado quais segmentos são repetidos e quais devem ser salvos. Quanto menor o tamanho do segmento, maior será a redução das redundâncias e o processamento da operação.
A principal limitação dessa abordagem é o fato de que, quando os dados em um arquivo são alterados (por exemplo, quando se adiciona um slide a uma apresentação do Microsoft PowerPoint), todos os blocos subsequentes no arquivo serão regravados e provavelmente serão considerados diferentes dos do arquivo original. Como resultado, o efeito de redução é menos significativo.
A desduplicação de comprimento variável é uma abordagem mais avançada, que divide os segmentos com base em seus padrões de dados internos. Essa tecnologia encontra padrões naturais ou pontos de quebra que podem ocorrer em um arquivo e então segmenta o dado de acordo com essa identificação. Assim, mesmo se houver alteração no arquivo e o bloco mudar, a desduplicação de comprimento variável poderá encontrar os segmentos repetidos.
Conclusão
Em data centers consolidados a desduplicação a nível de bloco é uma excelente solução, pois a virtualização cria blocos muito grandes e suas informações possuem um elevado grau de redundância. Assim, essa tecnologia consegue identificar quais segmentos desse bloco foram alterados. Isso permite elevados índices de redução no armazenamento, além de menor processamento, afinal só será necessário armazenar pequenos pedaços alterados e não a totalidade do bloco.
Nesse contexto de ambientes consolidados, o backup também é favorecido utilizando soluções com desduplicação em bloco. Por ser uma cópia, ele possui um alto volume de dados redundantes e, portanto, a desduplicação consegue melhores índices de redução. Nesse caso, um servidor físico com 15 máquinas virtuais, por exemplo, poderá diminuir a janela de backup copiando apenas os segmentos novos do bloco de dados desde o último backup.
Com a desduplicação em nível de bloco, quanto mais os dados são salvos, maior é o índice de redução das duplicidades. Com isso, o ambiente de TI economiza espaço no armazenamento, pois apenas os segmentos de dados únicos são armazenados, se essa desduplicação for realizada na origem, também ganha em rede, pois não será necessário enviar todo o volume de dados, apenas os desduplicados e também em espaço físico, já que essa tecnologia facilita a consolidação do data center.