O mito que a compressão de dados é igual a desduplicação
Cada vez mais as organizações buscam a consolidação de seu datacenter, com objetivo de atender à crescente demanda de armazenamento e processamento de dados. Para você ter uma ideia, em um recente estudo do IDC foi estimado que até 2020 haverá 44 zetabytes de informações no mundo. Agora, imagina quanto será investido em backup para dar conta de todos esses dados? Foi por causa desse cenário que a compressão e a desduplicação ganharam destaque nas soluções de proteção de dados.
Muitas pessoas confundem os dois conceitos e acreditam que são a mesma coisa. Porém, apesar de ambas serem algoritmos responsáveis por eliminar redundâncias de dados e, portanto, reduzirem o volume da informação, a desduplicação e compressão são tecnologias bem diferentes. Entender essas diferenças é fundamental na hora de definir ou configurar a sua solução de proteção de dados. Entretanto, para compreender as distinções entre essas duas tecnologias, é necessário antes de tudo esclarecer o que são e como funcionam cada uma.

O que é compressão de dados?
Comprimir não é reduzir o número de arquivos, mas diminuí-los. Essa técnica utiliza algoritmos para reduzir o número de bytes necessários para representar um dado que pode ser um arquivo, uma imagem ou um texto. Como a compressão faz isso? Através da eliminação de dados redundantes. Segundo essa lógica, a maioria dos dados possuem informações redundantes que podem ser reduzidas se escritas com uma nova regra (protocolo / codificação). De acordo com essa regra, quanto mais um dado é repetido menor será o tamanho do arquivo após a compressão.
Exemplificando.
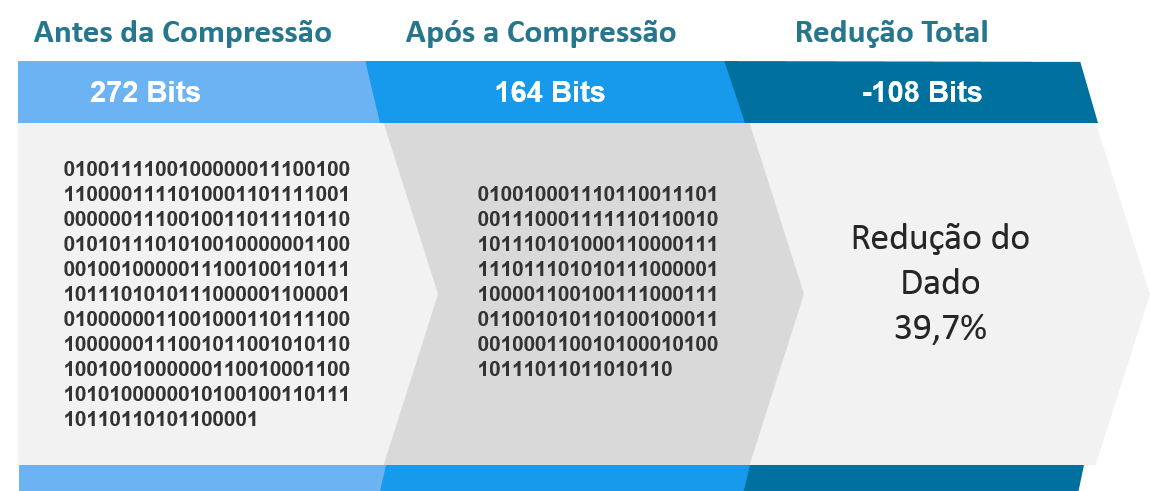
O blog do Ricardo Costa tem um ótimo exemplo sobre compressão. Transformando a seguinte frase em bits “O rato roeu a roupa do rei de Roma”, verificamos que é muito grande para armazená-la. Cada caractere é o conjunto de 8 bits ou um byte, ou seja, essa frase, inicialmente, possui 34 bytes. Então decidimos comprimir. Para isso separamos os caracteres mais repetidos na frase e o valor binário de cada.
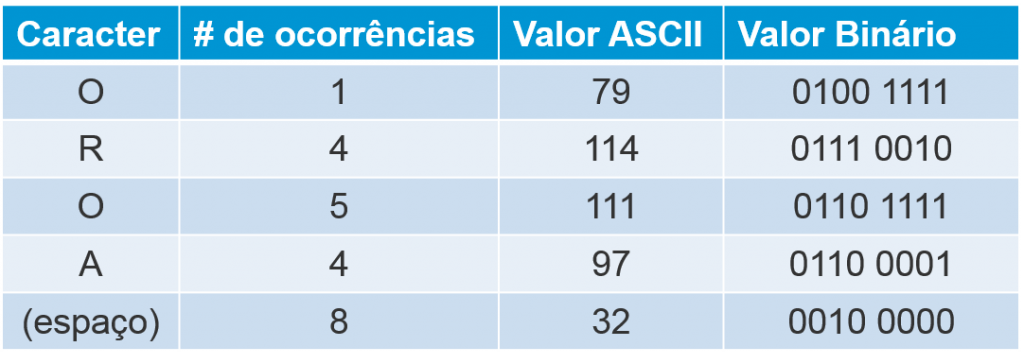
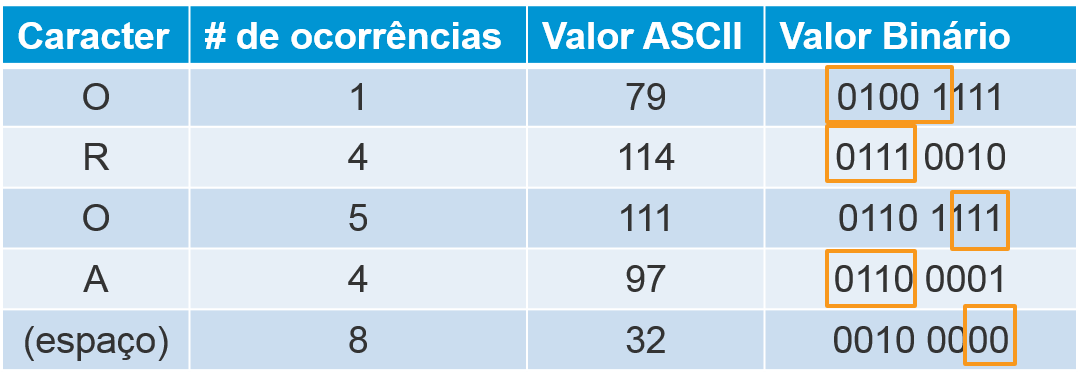
Ao realizar a análise de ocorrência das letras, percebemos que o (espaço) é o que mais se repete, portanto sua redução de bits será maior, seguido da letra “o” e assim por diante. Feito isso é realizada a redução dos bits de cada letra através de apontadores para as palavras redundantes. Isso significa que será escrito um novo valor binário diminuído e este deve ser declarado em uma espécie de dicionário, como o abaixo:
Como funciona a desduplicação?
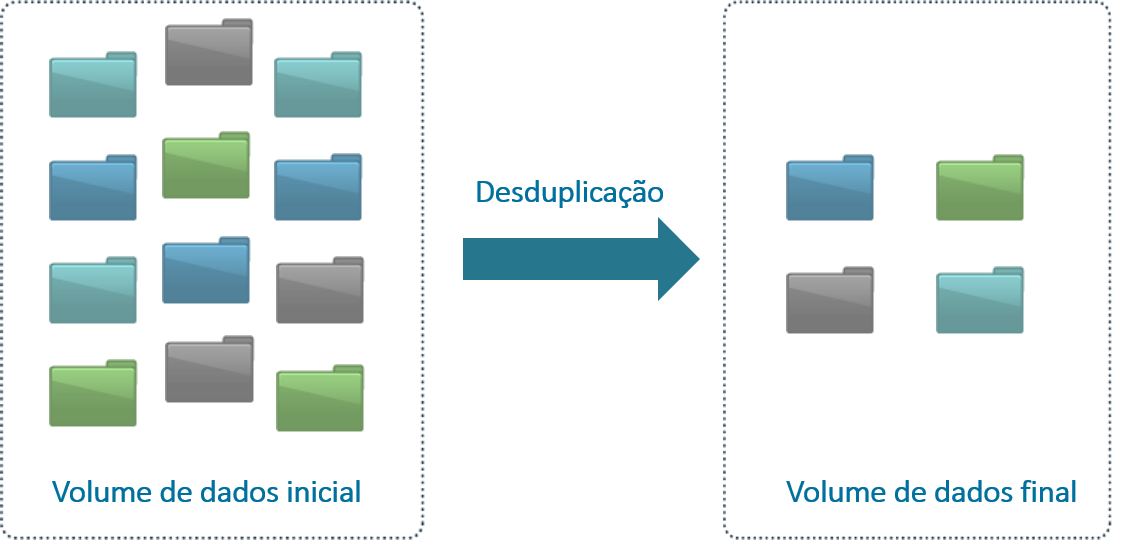
Mesmo possuindo o mesmo “espírito de trabalho” da compressão que é “eliminar dados redundantes”, a desduplicação busca este objetivo de forma diferente da compressão. A desduplicação elimina os dados redundantes através da retenção de somente uma única cópia deste dado, ou seja, o ganho de espaço é obtido com a substituição do dado duplicado por referência (ponteiro) a somente uma cópia do dado.
Para entender melhor a sutil diferença com a compressão, talvez seja interessante pensar desta forma: Enquanto a compressão há a retenção de todos os dados duplicados de uma forma mais econômica (com a substituição de uma codificação de vários bytes por outra codificação de poucos bytes), a desduplicação elimina totalmente as duplicidades retendo somente uma única vez o dado. Esta diferença de concepção permite que a desduplicação tenha maiores possibilidades de uso e aplicação como por exemplo várias granularidades (arquivos e blocos), abrangências pontuais/locais (arquivo) ou global (em todo o storage) com desempenho e segurança.
A desduplicação pode ser realizada a nível de arquivo ou de bloco. No entanto, para explicar as diferenças entre desduplicação e compressão de maneira inicial, vamos utilizar a desduplicação mais simples, que no caso, é em nível de arquivo.
Essa tecnologia elimina os arquivos redundantes, através da comparação com os arquivos armazenados. Caso esse arquivo já tenha uma cópia no local de armazenamento, ele será eliminado e um ponteiro será criado nessa cópia, informando a localização do arquivo original. O grande problema desse tipo de desduplicação é que, se o arquivo for alterado, ele será considerado um novo arquivo, ou seja, será salvo. O que não ocorre com a desduplicação de bloco, pois é mais granular, a nível de bits.
Exemplificando:
Imagine que 1000 pessoas recebam um relatório de 1 MB por e-mail da empresa. Se cada destinatário salvar esse relatório localmente, ele será replicado 1000 vezes. Esses arquivos repetidos consumirão 1 GB de espaço de armazenamento.
A desduplicação de arquivo salva apenas uma cópia do relatório no backup e substitui as outras 999 cópias por indicadores que apontam para a única cópia. Portanto, ao realizar uma desduplicação, o volume final de todos os arquivos salvos seria 1 MB.
Por outro lado, se aplicarmos a compressão ao invés da desduplicação, a mesma não reduziria o número de arquivos, portanto ainda haveriam 1000 arquivos, contudo cada qual com seu tamanho reduzido. Supondo que a taxa de compressão seja de 50%, nesse caso, o volume total dos dados será de 500 MB.
Conclusão
A desduplicação e a compressão são funcionalidades e não produtos. O que significa dizer que é uma tecnologia que muitos fornecedores incorporaram em softwares e appliances. Podem estar presentes em várias camadas como: cliente, servidor ou armazenamento de produção; rede, através dos aceleradores de Wan; e no software ou armazenamento de backup e arquivamento.
Com a desduplicação é possível reduzir muito mais dados do que com a compressão, porém isso não significa que a compressão não deve ser utilizada até porque o custo/benefício da compressão em alguns casos pode ser melhor do que a desduplicação. É notório em alguns casos, como em File system e emails, os quais tendem a ter volumes absurdos e altíssimo nível de duplicações, a grande vantagem da desduplicação, pois sua taxa de redução será muito superior à da compressão. Em algumas implementações, ambas as tecnologias são utilizadas, com a desduplicação e compressão juntas atingindo taxas ainda maiores de redução de dados.
Leave a Comment
Your email address will not be published. Required fields are marked *